As a part of my seminar at the University, I got an opportunity to explore ideas related to integrating Knowledge to a Neural Network to enhance its performance. Just sharing some pretty interesting ideas here.
Expert systems are the ones that provide a clear explanation while decision making. Incorporating this to a neural network would enable the neural network to outperform its baseline model in terms of accuracies and explainability.
Considering an application of time series forecasting — let’s say, stock price prediction, or more relevant, let us consider forecasting COVID-19 cases over a period in a region. Just feeding the model with historical cases and expecting it to give a valid prediction, might, from my perspective, be flawed as several external factors need to be considered. Factors like the changes in the precautionary measures by the government, the lockdowns that were put to place, social distancing that took shape over a period, age groups that get affected over the period, etc.
There has to be a way we can embed all the above extra relevant information to the neural network to make more realistic /explainable predictions.
The explainable part can be analogous to the explainable aspects that come into play when considering Computer Vision applications in Neural Networks like visualizing gradients, visualizing activation maps, etc.
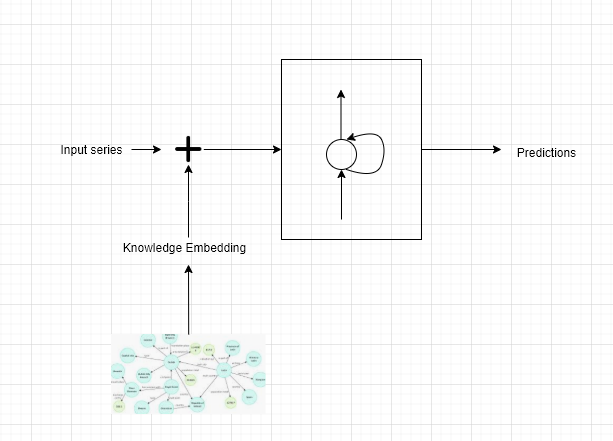
The first idea that was pretty cool, was to be able to get the knowledge embedding(KB) that is highly relevant to the input. KB is very similar to the word embedding (eg: word2vec, GloVe models) where the knowledge encoded as a triplet(eg <Corona, affects, Lungs>), is mapped to an embedding vector. There are a bunch of techniques available to determine the vector corresponding to the triplet. One such example is the TransE model. Once, Knowledge Embedding for an information triplet is known, the next step is to concatenate this with the normal input vector of #cases over a period.
In the case of COVID cases prediction, one can feed the model with not just the previous cases but also the current state of the region (ie in the form of a news article). Even better, one can maintain a knowledge graph as and when things unravel by updating the connections in the graph. Finally, during prediction, extract relevant sub-graphs from the knowledge graph, convert them to the KB embedding and feed it to the Neural Network. This allows the network to gain deeper insights into the situation.
There are variations in the above technique, like incorporating attention mechanism for the neighbours of a considered KB embedding, which I have touched upon in my survey paper:
https://arxiv.org/abs/2008.05972
The second idea talks about altering the states of a sequence-to-sequence model. A seq-to-seq model is used for predicting an output sequence given an input sequence (eg: Lang Translation). An encoder-decoder architecture is used for this purpose, where each stage of the model is made up of a Recurrent Neural Network (variants like LSTM, GRU can be used).
The expert knowledge is maintained as another trained RNN model. During training, at a given time step(state) of our Neural Network, we integrate the hidden state of our “to be trained ” model with the corresponding state of the trained RNN model via a gated mechanism — this ensures focussing on things at a granular level while predicting the output sequence.
The third idea considers the desired and predicted probability distributions of the expert knowledge and our model. It tries to train our model, by ensuring our model’s probability distribution P(X|Y) where Y can be the input sequence and X being the output sequence to stay as close (Kullback Leibler divergence) to the distribution of the expert knowledge. This desired probability distribution can be built either manually, considering another trained Neural Network, or using some kind of an n-gram model.
There are several such ideas that I came across, that includes using a CNN for forecasting, using Fuzzy Sets, etc, that can be checked in the attached survey paper. I think conveying all of them here might lead to confusion.
All in all, I think, providing the neural network with additional information that is relevant to the input, gives an edge to the neural network to make more realistic predictions. This enables us to attain a kind of synergy between an Expert system and a Neural Network to capture the best parts of both systems.