Begin.
It's been a while, caught up with exams, onset of overwhelming yet exciting subjects of the new semester.
So a couple things happened actually,
> Started exploring the implementation of basic neural network on the web. (without the optimization or even the validation part!). Main intention was to see the entire flow in action hopefully in a graph!).
> After some googling (there were ready codes available):
Here is what I tried to implement -
> I decided on a basic neural net structure, straying a bit away from what I wanted to be able to predict in the first place.
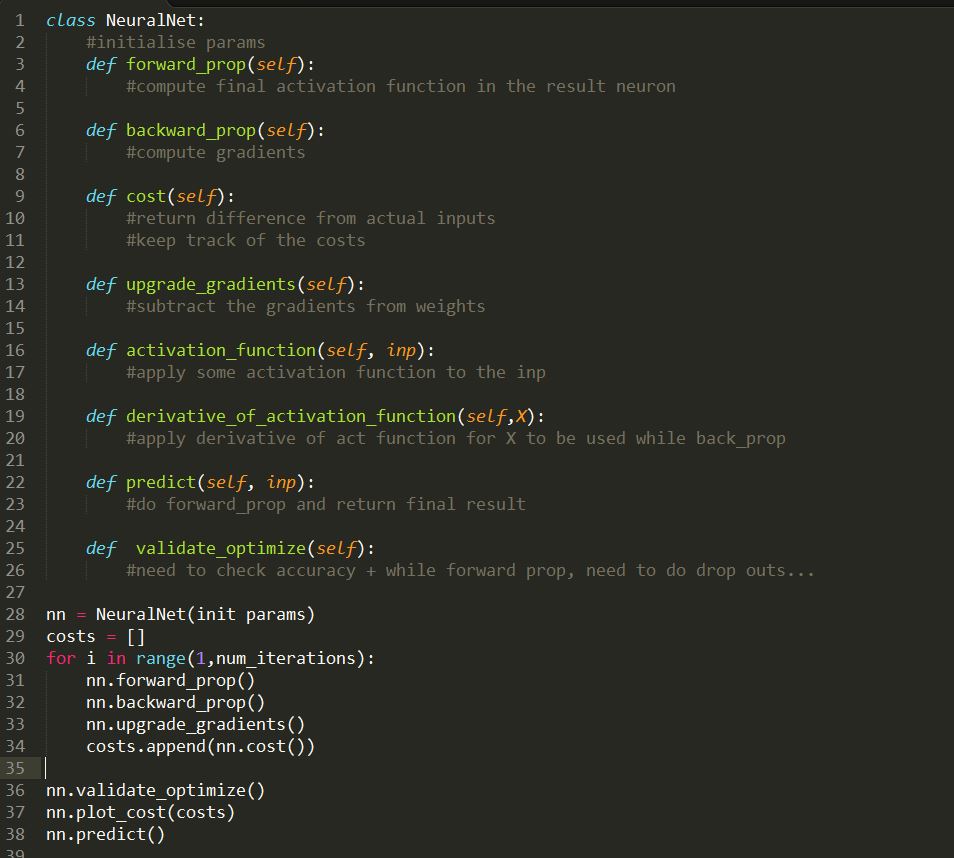
> This is what I wanted to implement

A few things that I explored on the way-
> I used a dataset that was given as a part of a course by my Uni, (Titanic survival dataset- which I think is available on Kaggle).
> I wanted to play with the dataset, hence explored a bit of Pandas - yet again, it is one powerful and beautiful utility! Using jupyter notebook as its just awesome.
> Realised Pandas understands data in terms of dataframes, awesome way for filtering, doing a basic EDA on the given data to get like an overview of the data.
> 1 important step which I had to unfortunately realise the hard way, was the part where I had to thoroughly 'clean' my data.
> Here, I explored why I was supposed to clean the data / How can i do all this in Python
1. Remove NaN - non numeric values.
2. Convert categorical data to numbers (Enumerations)
3. The important one was Normalisation - Sort of having all of the features in a standard scale. Like there could be a column A whose range is 1-5 and 1 more B whose range is 1000-60000. > So in this case, if they are used the same way, as pointed by this person on youtube, the weights assigned to those features might heavily rely on the numeric values alone and not its influence on the result - as in, if A has the value 5, B has 1000, B might be given the wrong weightage.
4. Hence normalize using, X = (val - mean) / standard deviation - Stand deviation describes the spreadness of my column.
5. To sort of squish the values of a column btw 0 and 1, I can use X = (val - min)/ (max - min)
6. Initialise the bias column (np.ones) to X.
> So I wanted to predict the age of the passenger given his/her features - something like, given his/her economic status(class), location....accompanied by .. price of ticket purchased... , try and guess their age.
After cleaning the data bit, I decided on the label (age)..
> O, I also need to squish the Y or labels between 0 and 1! as my NN gives me values between 0 and 1! Totally forgot to do this till the very end, hence I used to get faulty error function! Error function had errors :D
> Formed the backbone of the NN that had like 2 internal layers excluding the input and output layers.
> The weights to a layer followed the format:
ex on layer 1
[
[weight on neuron 1, weight on neuron2, weight on neuron 3 ], // for feature1
[weight on neuron 1, weight on neuron2, weight on neuron 3], // for feature2
[weight on neuron 1, weight on neuron2, weight on neuron 3] //for feature3
[0.1, 0.1, 0.1] //bias weights
]
> I had to initialise the weight matrices (numpy.random.rand) - initialise bias weights (0.1) as well.
> Multiplication between several matrices was a pain! was too hard to ensure the shapes of the matrices are to be maintained - obviously I could not figure stuff out myself, went wrong at several places real badly, hence I referred the web.
So the structure was something like:

> Also yes, for backward prop (climbing down the error hill), the gradients for all 3 weight matrices for 3 layers, unfortunately I referred the web for the ready made formula - but yes I understood the partial derivative part and how they derived the gradient wrt diff weight matrices using chain rule.
So this is the cost function (difference between actual and predicted values) that I plotted using Matplotlib

So yea, the flow seems okay, as in -
> Yes the cost function seems to be decreasing. So the offset btw the actual and predicted values seems to be decreasing at every run.
> But 1 main thing that I am not doing here is the validation and optimization part..
> This expects me to address train - cross validate (model evaluation) - test (error) part.
> And also if there is overfitting or underfitting in the model. Apparently there are techniques to prevent model from overfitting (the selected weights for features is highly inclined towards the training set and does not generalise well for new incoming data)
or
underfitting (the selected weights for features is highly generic and does not predict stuff well)
> Some of them are -
Have more data,
Regularization,
Drop Outs to prevent Overfitting.
Change network architecture
> Techniques to rectify underfitting -
Have more layers
More neurons in each layer
Change net architecture
TakeAways:
> Need to decide on the neural net architecture first - layers, neurons, learning rate, num_iterations and stuff.
> Data cleaning - data munging - data wrangling - to clean non-numeric values, enumerate categories, normalize the data(features and labels).
> Initialise weight matrices - add initial bias weights column (column of some 0.1 initially) as well!
> Add bias column (column of 1s) to the input features. (bias - used to fit the model better)
> Pandas for data exploration - dataframes, effective filtering, selection and manipulation of the data.
> Understand how the feature matrices are represented which when combined with the weight matrices results in activations that is passed onto the next layer.
> Ensure the shapes of matrices are maintained across layers.
> Understand how gradients for different weights are calculated using back prop and hence the partial derivatives (chain rule was confusing!)
> The chain rule formulas are faulty - as in
- the biases that were added in the beginning to the features and weight matrices had to be handled for each weights.
- had to transpose a couple results to ensure right shape is maintained. Was confusing! Hence copied off the formulas from the web.
> Satisfactory decrease in the cost function across iterations! Plot was nice to visualize:) but unfortunately have handled nothing.
> Need to incorporate train_cross-validate_test split for validation of the model.
> Also need to incorporate regularization, drop out to prevent overfitting(inclined to train data)
> Explore possibilities of underfitting as well.
> There is also something called gradient checking to double check if the gradient descent achieved in the model was right.
> Offf, that was a lot I had to explore in parallel with other things, I think some of them were incomplete...but its fine..I think I have a fair idea about the story..,
> for the next steps, with this background , I think I'll dive into CNN, and learn on the go types (Optimizations can be done directly wrt CNN)
> Have also enrolled for Coursera's Andrew NG's Deep Learning course. (One can audit this as well for free!)
> Have also audited the course on linear algebra on Coursera - the math for ML.. to sort of be able to appreciate the math better! Not sure if I can keep up.
Also, not sure if posting the code makes sense. I feel the satisfaction to see one's own code in action is awesome! So, even if a bit of effort is made to go out there, make an attempt to understand already written code snippets (which they say is far more challenging than writing ur own code), is worth it! :)
End.
It's been a while, caught up with exams, onset of overwhelming yet exciting subjects of the new semester.
So a couple things happened actually,
> Started exploring the implementation of basic neural network on the web. (without the optimization or even the validation part!). Main intention was to see the entire flow in action hopefully in a graph!).
> After some googling (there were ready codes available):
Here is what I tried to implement -
> I decided on a basic neural net structure, straying a bit away from what I wanted to be able to predict in the first place.
> This is what I wanted to implement

A few things that I explored on the way-
> I used a dataset that was given as a part of a course by my Uni, (Titanic survival dataset- which I think is available on Kaggle).
> I wanted to play with the dataset, hence explored a bit of Pandas - yet again, it is one powerful and beautiful utility! Using jupyter notebook as its just awesome.
> Realised Pandas understands data in terms of dataframes, awesome way for filtering, doing a basic EDA on the given data to get like an overview of the data.
> 1 important step which I had to unfortunately realise the hard way, was the part where I had to thoroughly 'clean' my data.
> Here, I explored why I was supposed to clean the data / How can i do all this in Python
1. Remove NaN - non numeric values.
2. Convert categorical data to numbers (Enumerations)
3. The important one was Normalisation - Sort of having all of the features in a standard scale. Like there could be a column A whose range is 1-5 and 1 more B whose range is 1000-60000. > So in this case, if they are used the same way, as pointed by this person on youtube, the weights assigned to those features might heavily rely on the numeric values alone and not its influence on the result - as in, if A has the value 5, B has 1000, B might be given the wrong weightage.
4. Hence normalize using, X = (val - mean) / standard deviation - Stand deviation describes the spreadness of my column.
5. To sort of squish the values of a column btw 0 and 1, I can use X = (val - min)/ (max - min)
6. Initialise the bias column (np.ones) to X.
> So I wanted to predict the age of the passenger given his/her features - something like, given his/her economic status(class), location....accompanied by .. price of ticket purchased... , try and guess their age.
After cleaning the data bit, I decided on the label (age)..
> O, I also need to squish the Y or labels between 0 and 1! as my NN gives me values between 0 and 1! Totally forgot to do this till the very end, hence I used to get faulty error function! Error function had errors :D
> Formed the backbone of the NN that had like 2 internal layers excluding the input and output layers.
> The weights to a layer followed the format:
ex on layer 1
[
[weight on neuron 1, weight on neuron2, weight on neuron 3 ], // for feature1
[weight on neuron 1, weight on neuron2, weight on neuron 3], // for feature2
[weight on neuron 1, weight on neuron2, weight on neuron 3] //for feature3
[0.1, 0.1, 0.1] //bias weights
]
> I had to initialise the weight matrices (numpy.random.rand) - initialise bias weights (0.1) as well.
> Multiplication between several matrices was a pain! was too hard to ensure the shapes of the matrices are to be maintained - obviously I could not figure stuff out myself, went wrong at several places real badly, hence I referred the web.
So the structure was something like:
So this is the cost function (difference between actual and predicted values) that I plotted using Matplotlib

So yea, the flow seems okay, as in -
> Yes the cost function seems to be decreasing. So the offset btw the actual and predicted values seems to be decreasing at every run.
> But 1 main thing that I am not doing here is the validation and optimization part..
> This expects me to address train - cross validate (model evaluation) - test (error) part.
> And also if there is overfitting or underfitting in the model. Apparently there are techniques to prevent model from overfitting (the selected weights for features is highly inclined towards the training set and does not generalise well for new incoming data)
or
underfitting (the selected weights for features is highly generic and does not predict stuff well)
> Some of them are -
Have more data,
Regularization,
Drop Outs to prevent Overfitting.
Change network architecture
> Techniques to rectify underfitting -
Have more layers
More neurons in each layer
Change net architecture
TakeAways:
> Need to decide on the neural net architecture first - layers, neurons, learning rate, num_iterations and stuff.
> Data cleaning - data munging - data wrangling - to clean non-numeric values, enumerate categories, normalize the data(features and labels).
> Initialise weight matrices - add initial bias weights column (column of some 0.1 initially) as well!
> Add bias column (column of 1s) to the input features. (bias - used to fit the model better)
> Pandas for data exploration - dataframes, effective filtering, selection and manipulation of the data.
> Understand how the feature matrices are represented which when combined with the weight matrices results in activations that is passed onto the next layer.
> Ensure the shapes of matrices are maintained across layers.
> Understand how gradients for different weights are calculated using back prop and hence the partial derivatives (chain rule was confusing!)
> The chain rule formulas are faulty - as in
- the biases that were added in the beginning to the features and weight matrices had to be handled for each weights.
- had to transpose a couple results to ensure right shape is maintained. Was confusing! Hence copied off the formulas from the web.
> Satisfactory decrease in the cost function across iterations! Plot was nice to visualize:) but unfortunately have handled nothing.
> Need to incorporate train_cross-validate_test split for validation of the model.
> Also need to incorporate regularization, drop out to prevent overfitting(inclined to train data)
> Explore possibilities of underfitting as well.
> There is also something called gradient checking to double check if the gradient descent achieved in the model was right.
> Offf, that was a lot I had to explore in parallel with other things, I think some of them were incomplete...but its fine..I think I have a fair idea about the story..,
> for the next steps, with this background , I think I'll dive into CNN, and learn on the go types (Optimizations can be done directly wrt CNN)
> Have also enrolled for Coursera's Andrew NG's Deep Learning course. (One can audit this as well for free!)
> Have also audited the course on linear algebra on Coursera - the math for ML.. to sort of be able to appreciate the math better! Not sure if I can keep up.
Also, not sure if posting the code makes sense. I feel the satisfaction to see one's own code in action is awesome! So, even if a bit of effort is made to go out there, make an attempt to understand already written code snippets (which they say is far more challenging than writing ur own code), is worth it! :)
End.