CNN contd..
Ok so far, I've understood -
>
Forward propagation - where I calculate the outputs for a given layer using the outputs from the previous layer by fusing them with previously initialised weight matrices.
> Gradient descent to calculate gradients that would be subtracted from the weights assigned to the neurons in order to minimize my error.
> The decrease in weights has to be done across ALL layers.
Consider the example:
The second layer weights has the shape (2,3) - to map 2 outputs of previous layer to 3 neurons.
Hence layer2's weights is given by a single matrix.
> layer 1's matrix : X = [x1 x2]... (1,2) shape
In reality X will be a 2D matrix, eg:
X =[
[f1,f2,f3], #row1 in our case, probably a row of pixel values of an image
[f11,f22,f33] #row2
]
W1 = [
[w11 w12 13], # maps x1 to all 3 neurons
[w21 w22 w23] # maps x2 to all 3 neurons
]... (2,3)
W2,W3.
similarly, for other weight matrices.
> So using the weight matrices in each layer, I calculate the activations of the next layer. (Matrix Ops)
> Next I need to calculate the final error J(W) = (actual value - observed value)/ total #avg
> J(W) depends on the final weights W3 which in turn depends on W2, that depends W1 which depends on the input features(X).., I think intuitively it makes sense as the next activations were calculated using previous weights to this layer and previous activations.
Now, I need to rectify my error a.k.a change my weights
>
Backpropagation - So I am backtracking starting from the last layer towards the first layer to see how each of the weight matrices is having an influence on the final error.
> I also realised in the last post, in order to get how a variable independently influences a function, I need to consider all other variables as constant and take the derivative of that function w.r.t the variable of interest. This is sort of the definition of a partial derivative of a variable.
> So I take the partial derivatives of the final error function with respect to individual weight matrices and propagate that back to the respective layers so that they can "tweak" their weights accordingly.
Something of this sort:
J(W) = (blah)(y-y^) #y - actual value
y^ = a(z(4)) #a-activation function
z(4) = a(3) * W(3) #W(3) is the weights used to reach layer 4 from layer 3
a(3) = act_function(z(3))
z(3) = a(2) * W(2)
a(2) = act_function(z(2))
z(2) = a(1) * w(1)
a(1) = act_function(z(1))
z(1) = X * w(1) # X- inp features
So I can say that -
changes in J w.r.t W2 =(change in J wrt y^)
*(change in y^ w.r.t z(4))
*(change in z(4) w.r.t a(3))
*(change in a(3) w.r.t z(3))
*(change in z(3) w.r.t W2)!!
Need to do this much which I then subtract from the existing W3. This is sort of equivalent to me "taking a step down" from that hill seen in previous posts (w.r.t W3!)..
> I have tried not to include any formula to sort of retain continuity, as formulas intimidate me! (although once I understood the story , it shouldn't be hard to understand them as well)
> With a decent background in derivatives, I could follow the backprop on the web with formulas.
(just skimmed through the one given in matrices.io website)
https://matrices.io/deep-neural-network-from-scratch/
> I just had to know the derivative of hyperbolic tanh as they have used this as activation
function(tanh)..
> Now that I know the story of forward prop, backward prop - how backward prop uses partial derivatives to carry backward the error caused by the weights.
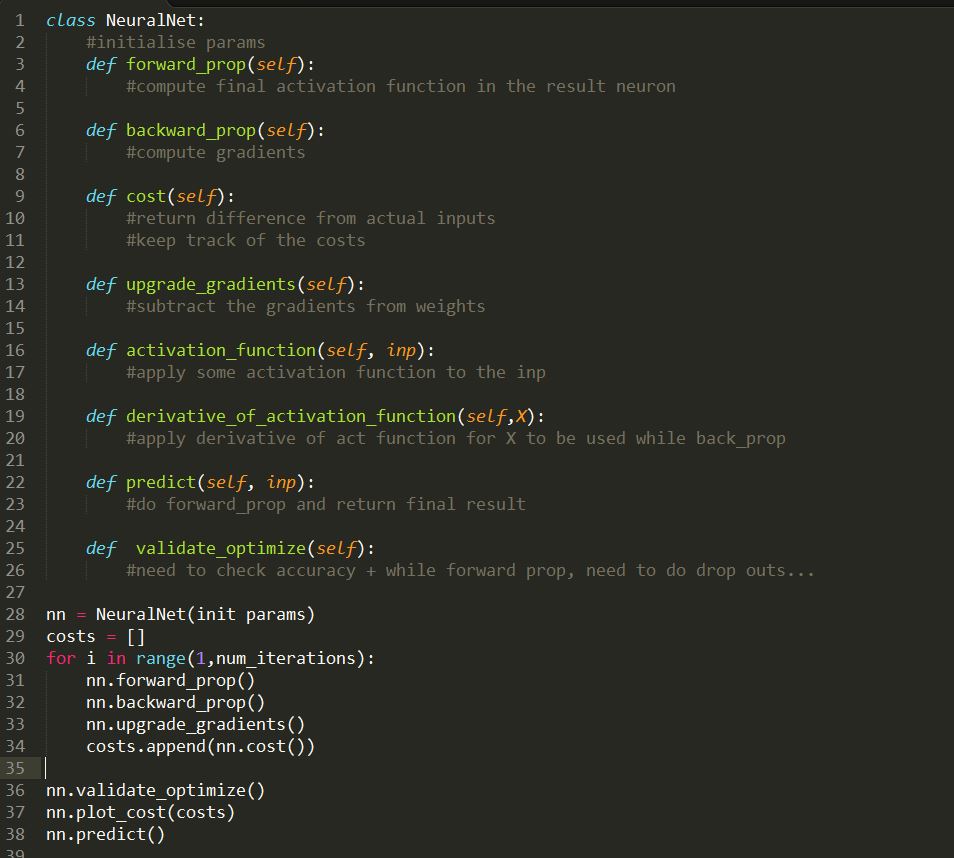
Pseudocode could be like:
for given number of iterations :
forward_propagation( ) #predictes stuff
backward_propogation( ) #calculates gradients of all layers in the backward direction
update_gradients()
> update the weight matrices (w = w - alpha * gradient_w).... alpha - learning rate
> the shape of a weight matrix w and gradient_w has to be equal as it is element wise subtraction
> the element wise subtraction implies how the weight of each feature is decreased accordingly - something like how important is a given feature on a neuron of a layer.
Bias:
> Had left this part for a while, as I thought it needed formulas for understanding bias.
> Now, the activation function that each layer determines, given by:
a(layer) = activation_function (z(layer))
where,
z(layer) = a(layer -1 ) * weight(layer - 1) #FMI : a(0) = feature set
> This activation is a nonlinear function that transforms the linear equation : features * weights so that patterns can be found, various other non-observable patterns can be found, using which probabilities of getting a value can be determined that squashes the result between 0 and 1.
> Some of the functions that I came across were the tanh(hyperbolic tanh(x)), Relu (rectified linear unit), Sigmoid - apparently there are lots of them, which one to choose - not discussing that now - ill probably refer this when required -
http://cs231n.github.io/neural-networks-1/ #refer commonly used activation functions.
> Now, on using a website
https://desmos.com, I plotted the tanh function to see how it looks
a = tanh(x)
looks something like
Clearly the y values are between -1 and 1 and I see the graph ascends to 1 at around x = 0.5.
But what if I want the graph something like,
The above graph has the equation
a = tanh(x -1.4)
Where the graph has a sharp ascend at around x = 1.4 ... probably this predicts stuff better...
>Now that -1.4 is a variable and I do not know the "correct" value with which I can determine based on the training set. And I call this value the "
bias" that helps me construct my model.
> Hence I put bias also as a part of the weight matrices which I will use in both forward and back propagation.
> The feature corresponding to bias will just be a row of 1s and corresponding row of 1s in the weight matrices.
>Now, because I am subtracting say a gradient w.r.t W3 from the actual matrix W3, it's obvious that both of their dimensions need to be the same.
eg : If a(3) has the shape (5,2) and a variable delta has the shape (5,1) and gradient_W3 = delta . a(3)
and the actual W3 has the shape (2,1) - I need to transpose the matrix a(3) to make it (2,5) so that
(2,5) . (5,1) = (2,1) which I can use for an element wise subtraction.
Handling bias in gradients..
>Bias - To cater to handling gradient of bias - in the eg:
z(3) = a(2) * w(2)
w(2) will have an additional row for bias, but its gone while z(3) is calculated, hence while calculating the error (backprop : gradient_w2 from z3) w3 is having an additional row for bias - need to cater to that as well, hence the formula for back-prop takes care of that as well.
> But the additional column added to the gradient for w3 cannot be used for back propagating the error calculation for w2, it needs to be removed.
> If the above is too difficult to understand, I can just stick to that website, it mentioned a bit clearly.
PS:
The formulas to calculate the gradients in backpropagation,
adjusting the matrices of activations (transposing) to match the weight matrices,
adjusting matrices to include bias corrections and re-adjusting such that they are not propagated
is all compiled in that website.
It might get complicated, I believe the formulas can just be briefly seen, just need to get a vague idea about what is happening.. But it's a nice exercise for the brain to try and understand the formulas from that website .
TakeAways:
- Forward propagation - calculate activations in each layer using previous layers' activations - finally predict value
- Use the above to calculate error.
- Back propagation : Starting from the last nodes, calculate the gradient wrt the immediate previous weight matrices (partial derivative) and use chain rule to propagate the error to previous layers (by taking partial derivatives of various weights ).
- Can check desmos.com to realise why we need biases.
- Update weight matrices using the calculated gradients from the previous step (don't forget learning rate - that decrease the step size while descending the hill)
- Adjust the activation and biases while back propagation.
- General pseudo code is given.
- Finally I think I have the stuff to have an end to end crude NN setup (without any error handlings)
- Shall try and implement stuff in the next one! (for sure this time! :-| wanted to have this post as I had left out backprop and bias)
End.